Privacy aspects
The privacy is one of the important aspects of data publishing, especially in this case where data are of the personal nature. For this reason, explicit identifiers such as names, addresses and phone numbers are commonly removed. However, anonymous respondents may by re-identified by combining other data such as birth date, sex, and ZIP code which uniquely pertain to specific individuals.
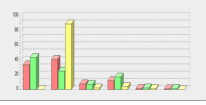
In our method the re-identification is impossible because of the "protecting" property of the underlying statistical model. As you can see in the figure below, the accuracy is very good for the "big enough" subpopulations, but rapidly decreases for combinations containing only few people. And finally, it contains practically no information about individuals (see the last row 1-3 people).
Therefore we can say that the proposed method guarantees privacy of the respondents.

Relative error distribution according to the subpopulation size.